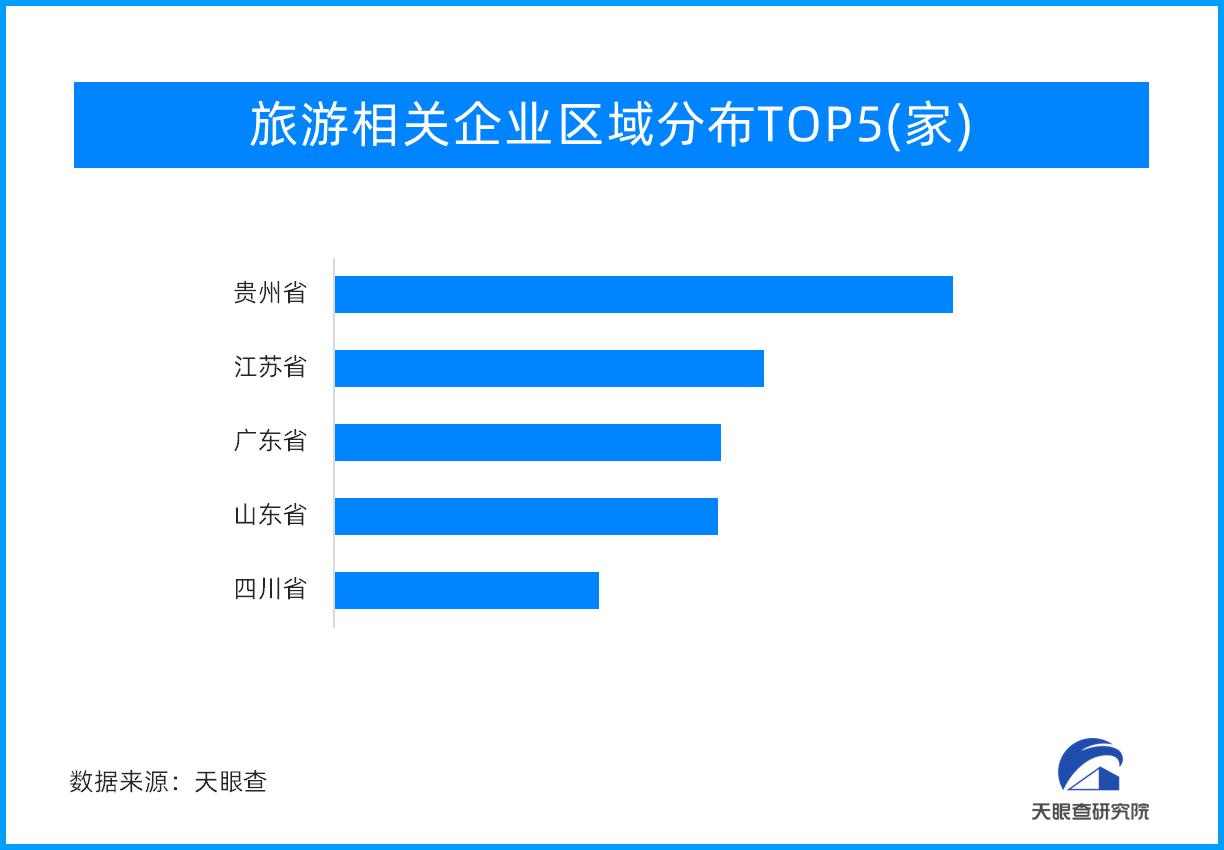
中国工程院院士高文:将打造2000亿参数自然语言大模型底座,性能对标Ch
发布时间:2023-07-07 09:47来源: IT之家阅读量:19488
,中国工程院院士、鹏城实验室主任高文在 WAIC2023 的昇腾人工智能产业高峰论坛上表示,鹏城实验室已启动脑海大模型计划,目标打造国内首个完全自主创新、开源开放的自然语言预训练大模型底座,参数级别达到 2000 亿,性能对标 ChatGPT。
IT之家注意到,高文本月早些时候还透露,“鹏城?脑海”大模型通过基于增强学习的大模型微调技术,该模型能够持续演进、快速迭代更新,输出内容符合中文核心价值观。面向数字政务、智慧金融、智能制造等应用场景,鹏城实验室将开放基于“鹏城?脑海”大模型底座的合作,共建国产自主可控预训练大模型健康生态。
高文此前曾提到,ChatGPT 的出现,使得以 AI 算力、大模型、通用人工智能为代表的人工智能技术进入了加速变革的“快车道”。实际上,ChatGPT 之所以对人工智能的发展带来如此大的反响,核心就在于它的 AI 大模型能力,而算力、数据和算法的三者结合正是 AI 大模型的制胜关键,也是通用人工智能发展的前进方向。
广告声明:文内含有的对外跳转链接,用于传递更多信息,节省甄选时间,结果仅供参考,IT之家所有文章均包含本声明。
声明:本网转发此文章,旨在为读者提供更多信息资讯,所涉内容不构成投资、消费建议。文章事实如有疑问,请与有关方核实,文章观点非本网观点,仅供读者参考。